stitchr
Stitch together TCR coding nucleotide sequences from V/J/CDR3 information
Contents:
Sometimes you need a complete TCR nucleotide or amino acid sequence, but all you have is limited information. This script aims to generate a coding nucleotide sequence for a given rearrangement (e.g. for use when generating TCR expression vectors) in those situations.
The script takes the known V/J/CDR3 information, and uses that to pull out the relevant germline TCR nucleotide sequences and stitch them together. Its modular approach can be used for the automated generation of TCR sequences for gene synthesis and functional testing, or for TCR engineering through supplying modified germline sequences.
Out of the box, stitchr works on all common jawed vertebrate TCR loci (alpha/beta/gamma/delta), for all species for which there is currently data available in IMGT.
What’s new in v1.3
(2025-04-25)
A couple of minor case use capabilities have been added in this version.
A
-nl / --no_leaderflag has been added, so that TCRs can be generated without a leader region (as had been requested in the Issues page). Note that this option should be avoided for construction TCR sequences for functional expression, as these regions encode the signal peptide and are thus required for proper polypeptide trafficking.A
-sn / --skip_n_checksflag has been added, allowing the production of TCRs with CDR3 junctions which do not begin with the classical conserved second cysteine when providing exact CDR3 junctions. Note that this option will only work for rearrangements which have deleted this CYS104 residue; in the absence of any N-terminal overlap (which previously was the Cys as a minimum), it now places the provided junction sequence with the first CDR3 residue in place of CYS104. (The only way to getstitchrto reliably produce rearrangements which have deleted beyond this position is to provide nucleotide sequence which extends further into the V region, in conjunction with the-sl / --seamlessflag.)In order to simplify tracking of different
stitchrupdates, script-specific versions have been removed and updates are tracked wholly through package-level versioning. This can be easily obtained by running the--versionoption in any of the command scripts, or--citefor a fuller description.
What’s new in v1.2
(2025-02-24)
There are a number of minor tweaks and quality of life improvements in the update from version 1.1.3 to 1.2.0, with the major changes aiming to improve repeatability and user convenience, including:
stitchrhas changed how it stores and handles data, as laid out in the stitchr output modes section…… Which has enabled outputting both
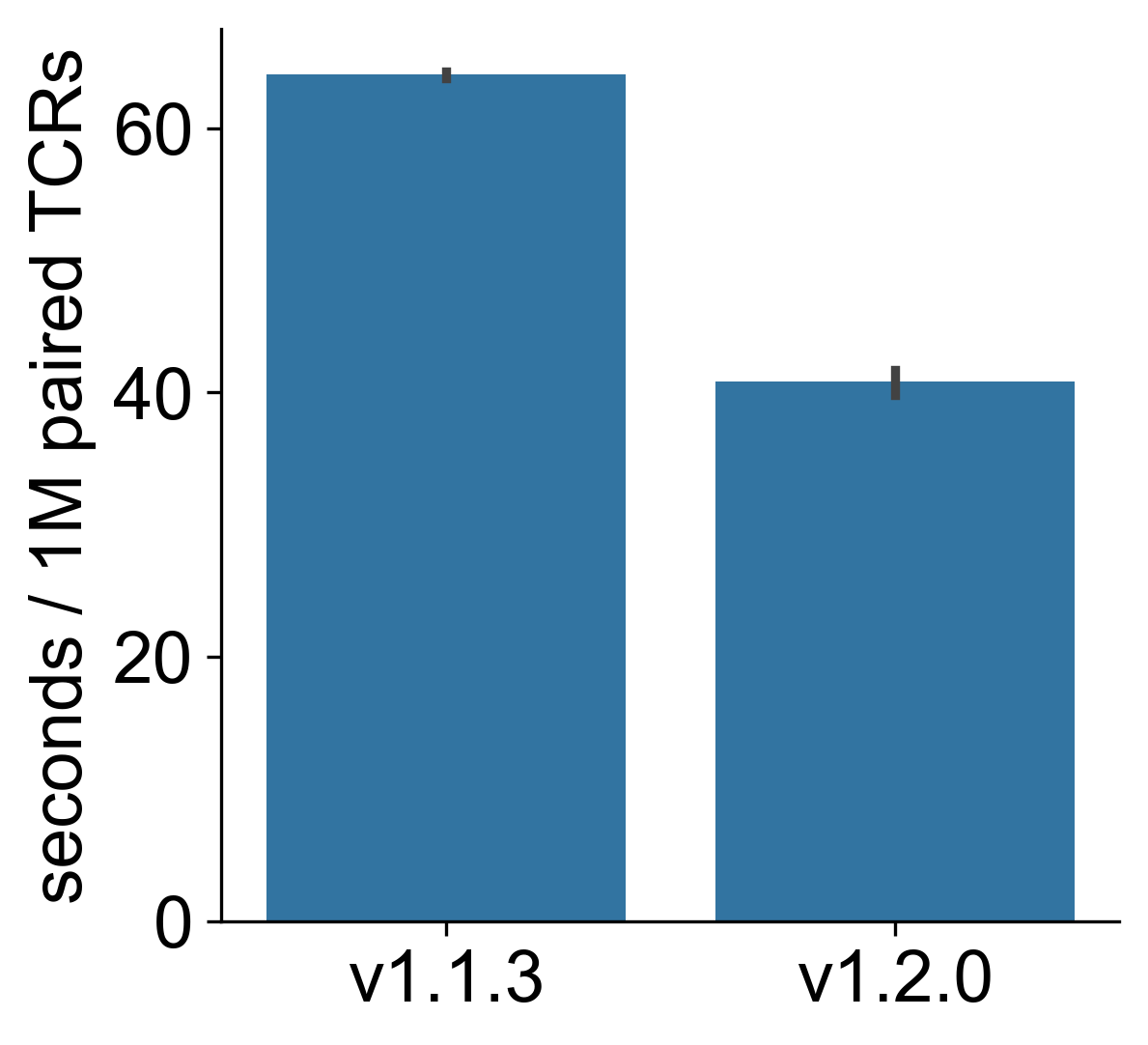
stitchrandthimbleresults as either JSON or GenBank files!stitchrdlhas also been updated to allow easier addition of FASTA reads to theadditional-genes.fastafile, as per the stitchr input data page.Finally some streamlining has increased the speed of the scripts, making
thimbleabout a third faster.See the below barplot, in which one million paired TCRs were processed with the old v1.1.3 and new v1.2.0.
Each version was run three times, error bars show 95% confidence intervals.